5、朴素贝叶斯Bayes Theorem
朴素贝叶斯是一种简单但极为强大的预测建模算法。
该模型由两种类型的概率组成,可以直接从你的训练数据中计算出来:1)每个类别的概率; 2)给定的每个x值的类别的条件概率。一旦计算出来,概率模型就可以用于使用贝叶斯定理对新数据进行预测。当你的数据是数值时,通常假设高斯分布(钟形曲线),以便可以轻松估计这些概率。 
朴素贝叶斯被称为朴素的原因,在于它假设每个输入变量是独立的。这是一个强硬的假设,对于真实数据来说是不切实际的,但该技术对于大范围内的复杂问题仍非常有效。
6、K近邻K-Nearest Neighbors
KNN算法非常简单而且非常有效。KNN的模型用整个训练数据集表示。是不是特简单?
通过搜索整个训练集内K个最相似的实例(邻居),并对这些K个实例的输出变量进行汇总,来预测新的数据点。对于回归问题,新的点可能是平均输出变量,对于分类问题,新的点可能是众数类别值。
成功的诀窍在于如何确定数据实例之间的相似性。如果你的属性都是相同的比例,最简单的方法就是使用欧几里德距离,它可以根据每个输入变量之间的差直接计算。
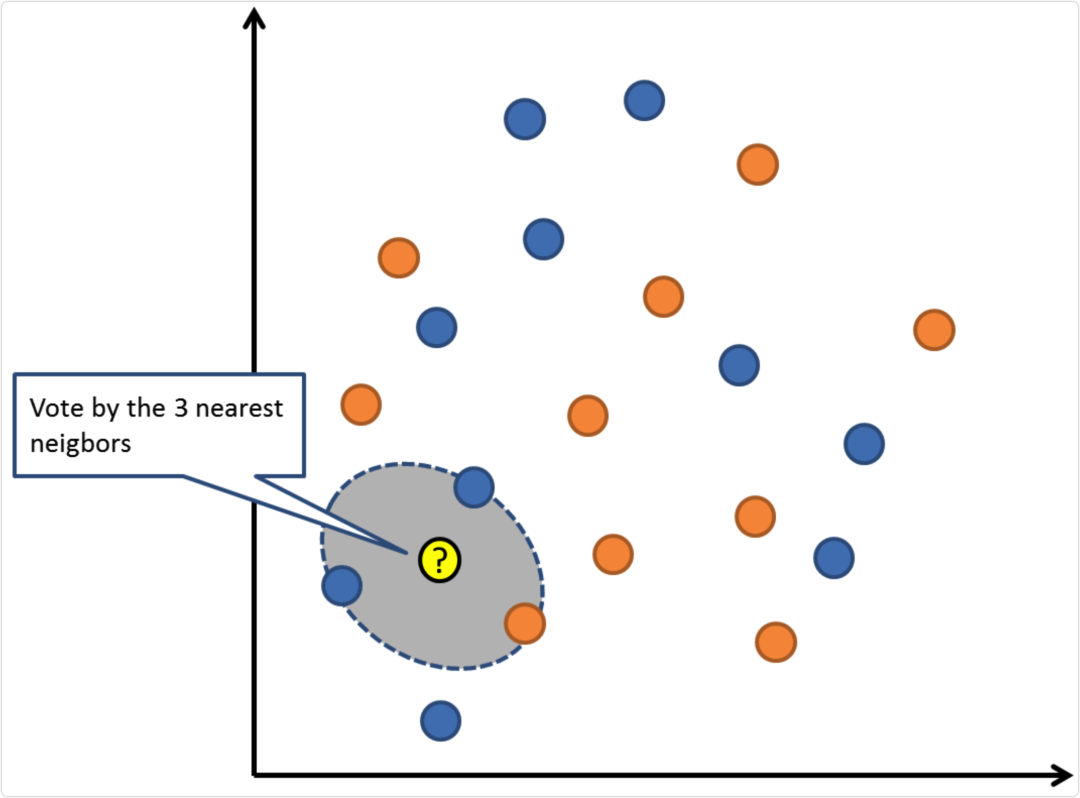
KNN可能需要大量的内存或空间来存储所有的数据,但只有在需要预测时才会执行计算(或学习)。你还可以随时更新和管理你的训练集,以保持预测的准确性。
距离或紧密度的概念可能会在高维环境(大量输入变量)下崩溃,这会对算法造成负面影响。这类事件被称为维度诅咒。它也暗示了你应该只使用那些与预测输出变量最相关的输入变量。
7、学习矢量量化Learning Vector Quantization
K-近邻的缺点是你需要维持整个训练数据集。学习矢量量化算法(或简称LVQ)是一种人工神经网络算法,允许你挂起任意个训练实例并准确学习他们。 LVQ用coebook向量的集合表示。开始时随机选择向量,然后多次迭代,适应训练数据集。
LVQ用coebook向量的集合表示。开始时随机选择向量,然后多次迭代,适应训练数据集。
在学习之后,coebook向量可以像K-近邻那样用来预测。通过计算每个coebook向量与新数据实例之间的距离来找到最相似的邻居(最佳匹配),然后返回最佳匹配单元的类别值或在回归情况下的实际值作为预测。如果你把数据限制在相同范围(如0到1之间),则可以获得最佳结果。
如果你发现KNN在您的数据集上给出了很好的结果,请尝试使用LVQ来减少存储整个训练数据集的内存要求。


